《Designing Data Intensive Applications》读书笔记 - 分区
上一篇讲数据库复制,对非常大的数据库,非常高的数据吞吐量,往往需要同时采用分区。每条数据记录只属于一个分区,但是它可能存储在多个不同的副本节点上。
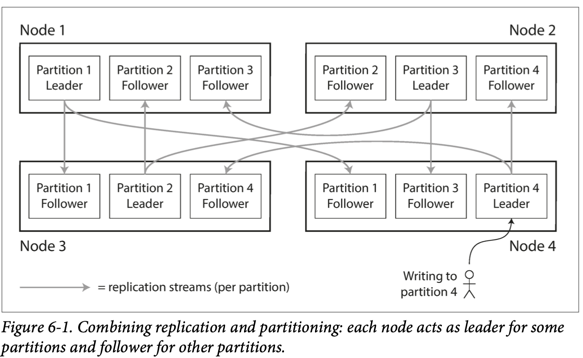
一个节点可以存储多个分区,对于主从复制来说,同时使用分区看起来像下图,每个分区的主库分配给一个节点,其它从库分配给其它节点。
Key-Value 数据分区
分区的目标是尽量将数据分散存储在各个节点上,查询负载均匀分布在各个节点上。如果分区不均匀,一些分区有更多数据承载更多的查询,我们称之为倾斜。负载比例比较高的分区称为热点。
最简单的避免热点方法是使用随机分区,缺点是读取时不知道数据在哪个节点,需要并行查询所有节点。
Key Range 分区
这种方式是分配一个连续范围内的键给一个分区。就像百科全书,字母范围 A-B 在第一卷,当然键的范围不必平均分配,因为数据本身也不是均匀分配的,某些键包含的数据可能比其它键多很多。
分区的界限可以由管理员手动设置,也可以由系统自动选择。这种分区的好处是,范围扫描非常高效,缺点是某些访问模式可能导致热点。比如选择日期作为 key 的话,最近日期的数据分区很可能成为热点。
所以,在选择 Key 时需要谨慎。
Key 的哈希分区
因为倾斜和热点的问题,许多分布式存储使用哈希函数决定分区。不幸的是,这种方式不支持高效的范围查询。Cassandra 折中了两种策略,组合键,先按范围分区,再按哈希分区。这种组合索引方式为一对多数据关系提供一种比较优雅的数据模型。
倾斜负载和热点消除
哈希函数可以减少热点,但是并不能完全消除。在极端情况下,比如社交媒体上的网红可能有大量的粉丝,这种情况下大量数据的写入可能都集中在一个分区。
现在,很多数据系统还不能自动补偿这种高度倾斜的负载,需要应用层来减少这种倾斜。比如,对于热点的键,可以将其分为多个键,增加两位数字的随机数可以分为 100 个键,这样可以将数据分散到多个分区。
当然,读取数据的时候需要一些额外的工作,需要读取所有的分区然后合并结果。 另外,需要维护和追踪哪些键被分割,这样可以在查询时合并结果。
分区和二级索引
本地二级索引
这种索引就是在同一个分区内,维护一个二级索引,也就是说每个分区都有自己的二级索引。
但是,读取本地二级索引的时候,需要在所有的分区上进行查询,有时称为 scatter/gather,即便查询分区是并发的,查询时间也受累于最慢的分区。
全局二级索引
与二本地索引对应,全局二级索引是在所有的分区上维护一个单独索引,当然不止存储在一个节点上,同时也有会自己的分区。
全局索引的好处是读取更快,不需要在所有的分区上进行查询,但是写入时会更慢。
实际中,更新全局索引通常是异步的。DynamoDB 的全局索引只支持最终一致性,而本地二级索引可以支持强一致性读。
分区再平衡
不管怎样,随着数据库的增长和机器变化,将数据和请求转移到的不同节点是必要的,这个过程称为分区再平衡。
基本需求:
- 再平衡之后,负载应该相对均匀
- 再平衡过程中,应该保持服务可用
- 不移动不必要的数据
再平衡的策略
为什么不能再哈希?因为再哈希会导致大量的数据移动,而且会导致热点。
- 固定分区数目
相对简单的方案:创建比较多的分区,分配多个分区给一个节点。比如一个节点开始有 10 个分区,当一个新节点加入时,可以从其它节点偷走一个分区。
移动数据时,将整个分区的数据进行移动。原则上,分区可以分割合并,但是固定分区运维简单,大多数固定分区数据库不提供分区分割合并的功能。
通常分区数目在数据库创建时就固定了,分区的数目要足够大,相对于将来增长的节点数量。当然分区数据过多会增加固定开销。所以选择一个合适的分区数目是很重要的。 - 动态分区数目
固定数目分区需要一个合适的固定边界,如果边界配置不合适,可能会导致数据很不均匀。动态分区在分区超过一个阈值时,自动分裂,当分区数据过少时,自动合并。
一个优点是,分区数目适配总的数据量。数据量小的时候,分区比较少,固定开销就小。 - 节点比例分区
第三种方案让分区数据量和节点数目成比例,当节点数目增加时,分区数目也增加。
自动还是手动
全自再平衡很方便,但是有些不可预测。再平衡是一个很昂贵的操作,需要重新路由请求,移动大量数据。如果操作不同,这个过程可能导致网络过载,节点负载过高。
请求路由
分区完成之后,留下一个问题,客户端请求时如何知道数据在哪个分区。这个普遍的问题又叫服务发现。
有几种方法:
- 允许客户端连接任意节点 如果那个节点碰巧有数据,就直接返回,如果没有,就转发请求到正确的节点,收到回复时转发回客户端
- 代理节点,客户端连接到代理节点,代理节点知道数据在哪个节点,然后转发请求到正确的节点
- 客户端知道分区和分区节点的映射
不管哪种方法,都需要给定组件知道节点上的分区分配。很多分布式系统依赖独立的协调服务像 ZooKeeper.Cassandra 采用不同的方法,采用 gossip 协议,节点之间相互通信,知道数据在哪个节点。请求可以发送到任意节点,节点会转发请求到正确的节点。
总结
这一章内容比较简单,有意思的是分区再平衡的问题,还有最后关于请求路由的问题。

