《The DynamoDB Book》读书笔记
同事推荐的一本书,只有英文电子版。作者是Alex DeBrie,之前介绍过,是单表设计的推崇者。
这本书前面部分几个章节介绍 DynamoDB 的基本概念,后面部分是一些实际的设计案例。
1. 什么是 DynamoDB
DynamoDB 的几个特性使用过的基本都知道:键值或宽列数据模型、无限扩展、HTTP 连接、IAM 鉴权、弹性定价、DynamoDB Streams、无需管理。
什么时候使用 DynamoDB: 超大规模应用、Serverless 应用、(大多数 OLTP 应用,缓存,简单数据模型)。我们现在的应用是无服务应用,毫无疑问选择 DynamoDB 。
另外我想强调的一点是 DynamoDB 能够满足绝大多数 OLTP 应用需求,当然现实中开发效率上确实不如成熟的关系性数据库。
2. DynamoDB 的概念
Table, Item 和 Attribute, Primary Key, Secondary Index 和 item collection(相同 partition key 的item)。
Primary Key 有两种类型:Simple Primary Key 和 Composite Primary Key。Simple Primary Key 只有一个属性,Composite Primary Key 有两个属性,分别是 Partition Key 和 Sort Key。很多时候使用 Composite Primary Key 是最好的选择,因为可以支持更多的查询需求。
Secondary Index 有两种类型:Local Secondary Index 和 Global Secondary Index。Local Secondary Index 只能使用相同的 Partition Key,Global Secondary Index 可以使用不同的 Partition Key。Global Secondary Index 更常用,因为更灵活。
另外介绍了一些高级概念:DynamoDB Streams, TTL, Partitions, Consistency 还有 DynamoDB Limits (Item size 400K, result 1MB, Single Partition 3000 RCU or 1000 WCU),
实际中很少会触及这个限制,遇到时都是非常极端的场景,比如 Item size 400K,我们遇到过一次,原因是将 DeviceId 存在 User item 中,每次 E2E 测试都会新增一个 DeviceId,突然一天测试开始失败因为 User item 超过 400K。
3. DynamoDB API
作者将 DynamoDB 的 API 分为三类:基于 Item 的操作、Query 和 Scan。
基于 Item 的操作有 GetItem, PutItem, UpdateItem, DeleteItem,对指定的 Item 进行操作增删改查,必须指定 Primary Key,修改数据只能修改一个 Item。即便能够使用 PartiQL 语法像 SQL 一样查询或更改,也不能批量修改数据。
Query 是根据 Partition Key 获取多个 Items 甚至不同实体类型,一再强调的是同一个 Partition Key 下的 Sort Key 是有序的,可以使用 Sort Key 进行范围查询,性能接近 O(lgn)。
Scan 是全表扫描,更新索引的时候会用到。
下面是一个 Query API 请求的例子:
1 | items = client.query( |
刚接触的时候,DynamoDB 的 API 确实有点难用,就不能设计简单点吗?书中解释说,之所以这么啰嗦是因为这样设计基本不需要花时间解析请求,也就是说一切为了性能。另外,书中不建议使用 ODM 主要考虑是后面会提到的单表设计。
DynamoDB API 中的表达式
- Key Condition Expression 每个 Query 请求都会用到的,用于指定 Partition Key 和 Sort Key 的条件。
- Filter Expression 用于过滤结果,只返回符合条件的 Item。只是在返回结果之前过滤,不会减少读取的数据量(读数据请求依然受 1MB 限制)。
- Projection Expression 用于减少网络传输,只返回指定的属性。
- Condition Expression 用于 PutItem, UpdateItem, DeleteItem,用于指定操作的条件。
- Update Expression 用于 UpdateItem,用于指定更新的属性,比如自增,从集合中删除
4. DynamoDB 数据建模
本书首先解释了与关系数据库的区别:Joins 在超大规模数据上的限制, Normalization 带来的益处以及为什么 DynamoDB 不需要 Normalization。主要观点是存储成本很低以及数据完整性是应用层面的问题而非数据库层面的问题。
建模的步骤:
- 理解业务需求
- ERD 设计
- 列出所有的访问模式
- 选择 Primary Key
- 为其它访问模式添加 Secondary Index
作者比较推崇单表设计,之前的文章也讨论过单表设计的优势与考量,这里就不再赘述。
建模实现中的一些技巧:
- 将索引属性与应用属性分开
- 不同索引属性不复用属性名
- 添加 Type 属性
- 写脚本帮助调试
- 使用短的属性名
在我们的项目中数据存储大概是这样子的:
1 | { |
注意这儿用 pk sk gpk1 gsk1 而非更对应具体索引名是因为同一张表中有很多不同实体,比如同一张表中可能还有 user-audit,它们也在使用这些索引,像下面这样:
1 | { |
建议使用一个简单的库来简化上面的设计,我们使用的是同事写的一个库 dynaglue,项目内也有一些复用代码。
像上表结构,配置完成之后就可以开始实现和测试 UserRepoService 了。
5. 常用策略
一些常见的模式吧,大多数比较容易,看到例子就能明白。
一对多关系
- Denormalization 比如将用户地址直接存储在用户信息中
- 存储相关实体同一个 Partition Key 比如上面例子中将用户审计信息存储在同一张表中,同一个 Partition Key 下的 Item Collection,一条 Query 请求就可以获取到用户信息和用户审计信息。
- 使用 Sort Key 存储层级数据比如
#省#市#县这样的层级数据。
多对多关系
- 浅复制 比如班级中存储所有学生列表
- 邻接列表 比如电影角色
- 规范化 需要多次请求
过滤
- 用
Partition key过滤 - 使用
Sort key过滤 查询一个范围内的数据其实效率非常高 - 组合
Sort key比如status#timestamp - 稀疏索引 举例来说,工单状态,只有
open的工单才有open的索引,但是不能将状态作为Partition key,因为这样会导致数据分布不均匀,应新建单独的索引使用工单 ID 作为Partition key。 - 使用
Filter Expression这个上面提到过,只是在返回结果之前过滤,不会减少读取的数据量(读数据请求依然受 1MB 限制),可以减少网络传输数据量。
排序
- 基本排序 确保 Sort key 有序,比如全部大写,时间戳,Sortable ID 像
KSUID等。上面用户审计的例子是用时间戳作为 Sort key,实际中KSUID更合适。 - 可变属性排序 比如更新时间 因为我们不能直接更新 Primary Key,所以只能将这个属性作为 Secondary Index 的 Sort key。
- 升序和降序排序 ScanIndexForward
- Zero Padding 数字排序 比如
001002003这样的排序。
迁移
- 既有实体添加新属性
- 添加新实体
- 添加新实体到既有的 Item Collection
- 添加新实体到新的 Item Collection
- 既有实体添加新的访问模式 (新建二级索引)
- 使用并行扫描
Segment和TotalSegments
平时工作中都会涉及,但是除了新建索引,我们需要脚本更新索引,其它基本不需要关心,脚本更新索引的时候可以使用并行扫描。
其它策略
- 确保值唯一 conditionExpression attribute_not_exists
- 有序 ID 比如 ISSUE ID, 作为 Project 的一个属性,书中的例子是先自增这个 IssueCount ,然后用 IssueCount 创建 Issue。不完美,但是可以接受。
- 分页 不像关系数据库可以很容易获取到全部数据条数。
实例
书中介绍了 4 个例子,包括一个电商应用,这儿只记录下 Github 的例子因为这个大家比较熟悉。使用上面提到的建模步骤:
- 理解业务需求
- 画出 ERD
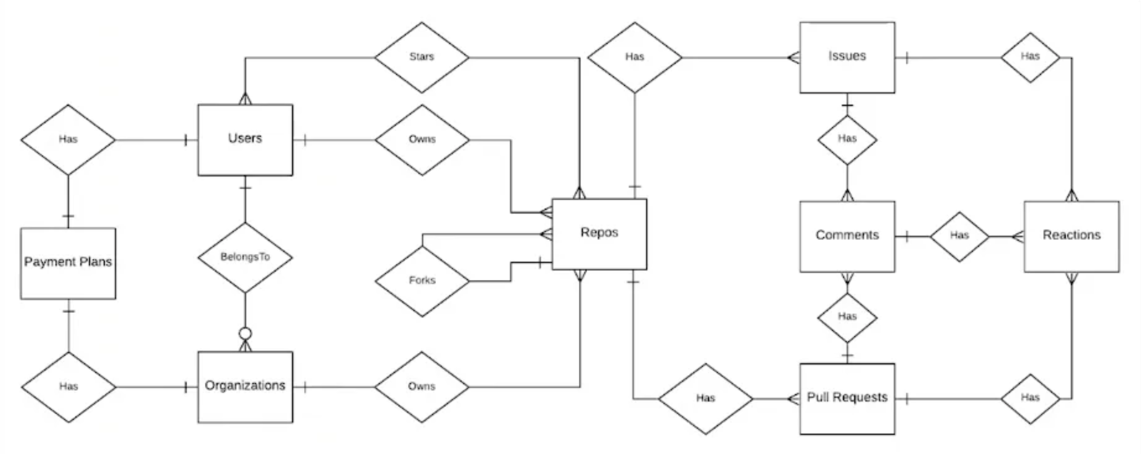
- 列出所有的访问模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41**Repo**:
- Get / Create Repo
- Get / Create / List Issues for Repo
- Get / Create / List Pull Requests for Repo
- Fork Repo
- Get Forks for Repo
**Interactions**:
- Add comment to Issue
- Add comment to Pull Request
- Add reaction to Issue / Pull Request / Comment
- Star Repo
- Get Stargazers for Repo
**User management**:
- Create User
- Create Organization
- Add User to Organization
- Get Users in Organization
- Get Organizations for User
**Accounts & Repos**:
- Get Repos for User
- Get Repos for Organization
- Get / Create Repo
- Get / Create / List Issues for Repo
- Get / Create / List Pull Requests for Repo
- Fork Repo
- Get Forks for Repo
**Interactions**:
- Add comment to Issue
- Add comment to Pull Request
- Add reaction to Issue / Pull Request / Comment
- Star Repo
- Get Stargazers for Repo
**User management**:
- Create User
- Create Organization
- Add User to Organization
- Get Users in Organization
- Get Organizations for User
**Accounts & Repos**:
- Get Repos for User
- Get Repos for Organization - 选择 Primary Key
- Repo PK:
REPO#<Owner>#<RepoName>SK:REPO#<Owner>#<RepoName>这儿考虑到到约束是给定用户下 Repo 唯一,如果使用随机ID,必须在新建 Repo 时检查 Repo 名是否唯一。 - Issue PK:
REPO#<Owner>#<RepoName>SK:ISSUE#<ZeroPaddedIssueNumber> - Pull Request PK:
PR#<Owner>#<RepoName>#<ZeroPaddedPRNumber>SK:PR#<Owner>#<RepoName>#<ZeroPaddedPRNumber>这儿不理解为什么不能像 Issue 一样使用REPO#<Owner>#<RepoName>作为 PK。 - IssueComment PK:
ISSUECOMMENT#<Owner>#<RepoName>#<IssueNumber>SK:ISSUECOMMENT#<CommentId>PK 相当于 Issue 唯一标识,SK 相当于 Comment 唯一标识。 - PRComment PK:
PRCOMMENT#<Owner>#<RepoName>#<PRNumber>SK:PRCOMMENT#<CommentId> - Reaction PK:
<TargetType>REACTION#<Owner>#<RepoName>#<TargetIdentifier>#<UserName>SK:<TargetType>REACTION#<Owner>#<RepoName>#<TargetIdentifier>#<UserName> - User PK: ACCOUNT#
SK: ACCOUNT# - Org PK: ACCOUNT#
SK: ACCOUNT# - MemberShip PK: ACCOUNT#
SK: MEMBERSHIP#
- Repo PK:
- 为其它访问模式添加 Secondary Index
GS1
REPO GS1PK:REPO#<Owner>#<RepoName>GS1SK:REPO#<Owner>#<RepoName
Pull Request GS1PK:PR#<Owner>#<RepoName>GS1SK:PR#<ZeroPaddedPRNumber>
GS2
REPO GS2PK:REPO#<Owner>#<RepoName>GS2SK:REPO#<Owner>#<RepoName>
Fork GS2PK:REPO#<OriginalOwner>#<RepoName>GS2SK:FORK#<Owner>
GS3
Repo GS3PK:ACCOUNT#<AccountName>GS3SK:#<UpdatedAt>
User GS3PK:ACCOUNT#<UserName>GS3SK:ACCOUNT#<UserName>
Org GS3PK:ACCOUNT#<OrgName>GS3SK:ACCOUNT#<OrgName>
这个例子可能比较适合单表设计,因为所有实体都是围绕 Repo 展开的,数据实体之间关系更多的是一对多,而不是多对多。如果把上面的设计再简化一点的话,就会显得一目了然更容易理解:
- REPO PK: REPO#RepoId SK: REPO#RepoId
- ISSUE PK: REPO#RepoId SK: ISSUE#IssueId 设计时甚至可以使用
ISSUE#IssueId作为 PK,就是之后还是要建二级索引支持根据 Repo 查询 Issue。 - PR PK: REPO#RepoId SK: PR#PRId
- ISSUE COMMENT PK: ISSUE#IssueId SK: COMMENT#CommentId
- PR COMMENT PK: PR#PRId SK: COMMENT#CommentId
总结
考虑很少人读过这本书,虽说这本书讲的内容很浅,在实际应用中涉及到单表设计还是值得借鉴。

