DynamoDB 单表设计的优势与考量
大多数开发都有关系数据库设计经验,在初次使用 DynamoDB 设计数据模型的时候,很容易陷入关系数据库的思维陷阱, 不自觉的遵守关系数据库设计的范式, 尝试将数据模型规范化,每个实体或实体关系都有对应的单独的表,通常称之为多表设计。
与之对应的是,将所有实体和实体关系都存储在同一张表中,毕竟 DynamoDB 是 Schemaless 的数据库,称之为单表设计。
这儿要强调的是,这两种设计只是极端的两点。可能也不是一个合适的命名,因为在实际应用中,单表设计并不意味着只能有一张表。
在两个极端之间,单表设计更倾向于将相关实体存入在同一张表中,多表设计则倾向将不同实体类型存入不同的表中。
在官方文档中,单表和多表设计比较时也较为推荐单表设计。本文就来根据实际经验,讨论下实际实践中单表设计的优势。
我们自己的项目采用的是单表设计,很大程度上受 《The DynamoDB Book》影响,作者 Alex DeBrie 是单表设计的推崇者。当然,我们项目中已经有十几张表,尽管我们已经尽量将相关实体存入同一张表中。
单表设计优点
1. 多个不同类型实体只需要一个请求
这个是单表设计的最大卖点,可以在一个请求中获取多个不同类型的实体,减少了请求次数,提高性能并降低成本。
《The DynamoDB Book》书中举的例子是用户信息和用户订单信息,如果是多表设计,用户信息表和用户订单表必须分别查询,而单表设计只需要一次查询。
在下面表,用户信息和订单信息使用相同的 Partition Key,在同一个 itemCollection 中,可以在一个 Query 请求中同时获取用户信息和订单信息。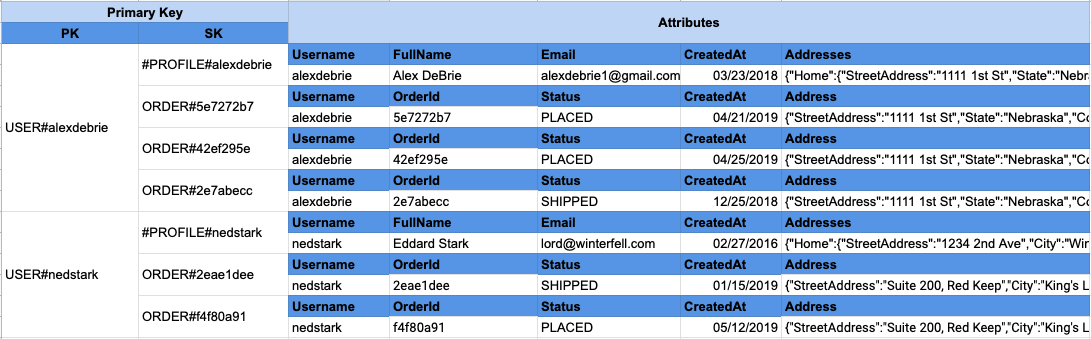
实际应用中的问题:上层的应用往往并不关心底层实现,很显然这两个不同的实体,在上层对应这不同的功能方法。更不用说,可能会有至少五六种不同的实体类型在同一个 itemCollection 中,除非刻意设计,否则很难利用到这条优点。
在 《The DynamoDB Book》中甚至刻意维护不同实体之间的顺序,以便更高效的查询。在实际应用中,我们根本不会关心同一个 itemCollection 中的实体类型的顺序,总的来说这个优点在实际应用中并不是很明显。
2. 降低账单成本和延时
两条记录总大小不超过 4KB 的单一请求是 0.5 RCU 一致性读
两次独立请求总大小不超过 4KB 是 1RCU 一致性读
两个独立数据的请求时间平均来说比单独的一次请求要长
账单的优点比较显而易见:减少了请求次数,自然减少了账单成本,通常单个实体记录不会很大,多个实体记录也不一定会有 4KB。
延时的优点也很容易理解,单次请求大多数情况下比两次请求要快。
问题是,即便在单表中,在实际应用中,上层服务并不知道下面的实现细节,还是会发出两个请求,这样这个点优点对我们来说一样并不存在。
3. 单表更容易管理
权限维护变少
容量管理更容易预测
监控更少的 Alarm
只需要在一张表上管理密钥
权限维护变少,同时带来的是权限粒度没有那么细,实际当中我们已经觉得我们的权限太细了,每个 Lambda 都配置不同的角色权限。
这些优点是实实在在的,单表设计更容易管理,不需要配置更多的配置,也不需要在每个 Lambda 中都添加对应表的访问权限。
4. 流量更顺滑
就像股票指数要比单一股票更稳定一样,单表设计的流量更稳定,更能充分利用 预置 功能。
单表设计的缺点
缺点不需要解释太多,主要是:
- 学习曲线陡峭
在理解了 DynamoDB 的核心概念之后,单表设计思想不难理解,只是遵循这种设计是有一定的成本的,并不认为学习曲线很陡峭。 - 同一张表中不同实体类型的数据需求(备份,加密)必须一致
- 所有的数据变更都会影响到 Streams
- 使用 GraphQL 更难实现
- 高级 SDK 比如 DynamoDBMapper 很难处理结果因为不同实体对应不同类
总结
总的来说,DynamoDB 的设计比较灵活,很多需求都可以满足,单表和多表之间也没有绝对的界限。
即便是单表的推崇者也只是推荐一张表对应一个服务,而不是整个项目只有一张表。
个人认为强调单表设计更多的是一种功矫枉过正,尝试让大家摆脱关系数据库的思维惯性。
在实际应用中,个人建议是无论如何先需要学习和理解 DynamoDB 的核心概念,然后根据实际需求来权衡单表和多表设计。
相关文章推荐:

